Memory Order에 관한 짧고 굵은 설명
이번에 M1에서만 발생하는 concurrency issue를 접하고 버그를 해결하는 과정에서 애매하게 알고 있던 memory order에 대해 정확히 짚고 넘어갈 수 있는 시간을 가질 수 있어 짧게 해당 내용을 남깁니다.
TL;DR

Relaxed는 함부로 쓰지 맙시다.
Relaxed는 명령어 재배치/최적화에 관한 어떠한 보장도 해주지 않습니다.
컴파일러가 보장해주는 유일한 사실은 Relaxed를 사용하는 atomic operation은 atomic 하다는 것입니다.

그것이 atomic operation 이니까요.
Atomic Operation
C++/Rust에서는 store / load / CAS 등의 atomic operation들을 제공해주고 있습니다.
이들은 인자로 다음 중 하나의 memory order를 받습니다.
memory_order_relaxedmemory_order_acquirememory_order_releasememory_order_acq_relmemory_order_seq_cstmemory_order_consume
대부분의 컴파일러에서memory_order_acquire로 간주되며 C++17부터 사양에 대한 정의가 다시 이루어지고 있습니다. 사용하지 마시기 바랍니다.
이 포스트를 다 읽으신 이후에는 모쪼록 아무 생각 없이 Relaxed나 SeqCst를 사용하는 일 없이 딱 필요한 ordering을 사용할 수 있으시면 좋겠습니다.
Relaxed
명령어 재배치에 대한 어떠한 보장도 해주지 않는, 가장 느슨한 memory order입니다. 컴파일러는 최적화를 위해 원하는 순서로 명령어를 재배치할 수 있으며, 유일한 보장은 해당 명령어가 atomic하게 일어날 거라는 것 뿐입니다.
간단한 예제를 통해 Relaxed가 문제를 일으키는 경우를 알아보겠습니다.
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
atomic variable x 와 y가 있을때,
Thread 1은 y를 읽고A → x에 읽은 값을 저장하고 있습니다. B
Thread 2는 그 반대로 x를 읽고 C → y에는 42를 저장하고 있습니다.D
이 때, r1과 r2가 42라는 값을 가지고 있을 수가 있을까요?
정답은 있다 입니다. 컴파일러는 우리가 적는 코드를 최적화하면서 실행 순서를 변경할 수 있습니다.
(물론 data dependency가 없어야 한다는 등의 전제 조건이 붙지만요)
memory_order_relaxed는 실제 실행 순서가
- Thread 1 : A → B
- Thread 2 : D → C
로 바뀌는 것을 막아주지 않습니다.
결국 우리는 y에 먼저 42를 저장하고 D → r1에 y값을 읽은 다음에A → 그 값을 x에 저장하고 B → r2에 x 값을 읽을 수도 있게 됩니다. C
Acquire & Release
위와 같이 원하지 않는 명령어 재배치로 인한 문제를 해결하기 위해 존재하는 게 바로 Acquire과 Release 입니다. 이 둘은 해당 스레드 내에서의 명령어 재배치에 관한 제약과 스레드 간의 제약을 추가합니다.
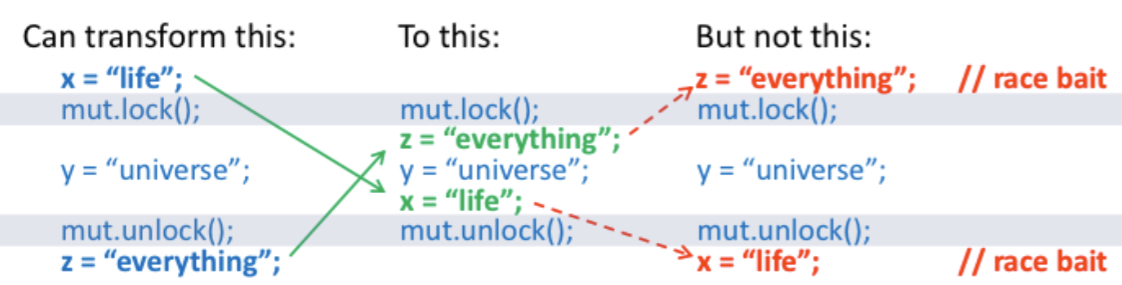
간단하게 생각하자면, acquire은 mutex lock, release는 mutex unlock이라고 할 수 있습니다. acquire과 release가 만드는 첫번째 제약 조건은 스레드 내 코드 실행 재배치입니다.
위 예시에서 볼 수 있듯이 acquire 이후에 나오는 코드들은 acquire 이전으로 재배치 될 수 없습니다. 마찬가지로 release 이전에 나오는 코드들은 release 이후로 재배치 되지 않습니다.
이는 acquire과 release 사이가 일종의 critical section처럼 작동하도록 도와줍니다.

두번째 제약 조건은 concurrent programming 함에 있어서 중요한 스레드 간에 적용됩니다. (relaxed를 사용하면 안되는 가장 큰 이유죠!)
release store를 통해 저장된 변수에 acquire load로 접근하는 스레드는 release store가 저장하기 전까지 작업한 모든 메모리 변경 사항을 볼 수 있음이 보장됩니다.
A release store makes its prior accesses visible to a thread performing an acquire load that sees(pairs with) that store.

한가지 더 sequential consistency를 보장하기 위해 적용되는 마지막 제약 조건은, 각 acquire과 release는 서로 재배치 될 수 없다는 것 입니다.
위의 그림에서 보이듯이 acquire → release가 순으로 있다면, 기존 제약 조건에 의해 release가 acquire 위로 재배치 되거나, acquire이 release의 아래로 재배치 될 수 없습니다.
하지만 release → acquire 순으로 작성된 코드에서 기존 제약 조건만 있다면 acquire과 release의 순서가 바뀌도록 재배치 되는 것을 막을 방도가 없습니다. 이를 막기 위해 추가된 것이 마지막 제약조건. acquire과 release는 서로 재배치 될 수 없다 입니다.
번외: 왜 M1에서만 버그가 발생했을까?
대부분의 PC를 비롯해 많은 환경에서 x86-64 아키텍처를 사용합니다.
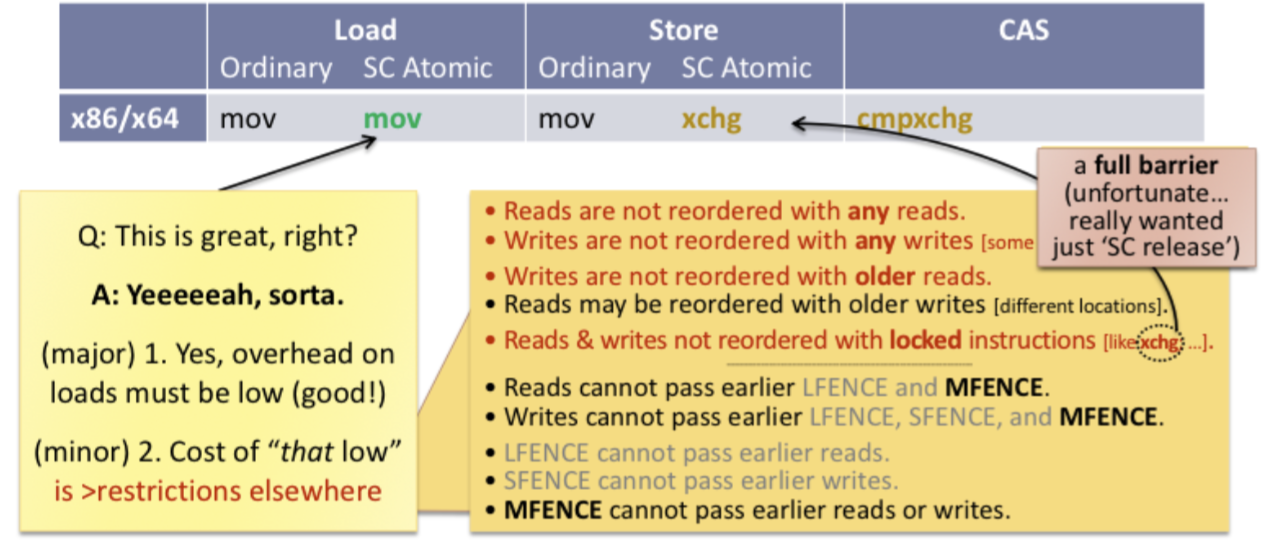
x86-64는 꽤나 오래전에 개발되었으며, 제약 조건이 강한 memory model을 사용하고 있습니다. 여기서 제약 조건이 많다 == 최적화 하기 힘들다 라고 이해하시면 되겠습니다. 그렇기에 가장 좋은건 sequential consistency를 보장하는 내에서 내가 요구하는 만큼만 제약하면 좋겠지만… 뭐 다 이유가 있는 법이죠.
- Reads are not reordered with any reads.
- Writes are not reordered with any writes. (some exceptions)
- Reads & writes are not reordered with locked instructions(e.g.
xchg) == Full fence - Reads may be reordered with older writes (different locations)
읽기는 다른 읽기와 재배치가 안되고, 쓰기도 다른 쓰기와 재배치가 안되고, atomic store는 다른 읽기/쓰기와 재배치가 불가능하고… 많은 환경에서 x86이 쓰이고 있는데, 잘못된 relaxed를 사용해도 큰 문제가 발생하지 않는 가장 큰 이유 이지 않을까 합니다.
M1은 많은 컴퓨터가 사용하는 x86-64 아키텍처가 아닌 ARMv8 아키텍처를 사용합니다. 정확한 memory model은 찾지 못 안 했지만 x86-64에 비해서는 훨씬 최신 아키텍처인만큼 최적화를 위해 제약 조건이 훨씬 완화된 것으로 알고 있습니다.
부록: compare_exchange_weak vs compare_exchange_strong
_weak와 _strong의 차이점은 _weak의 경우 spurious failure 즉, 거짓 음성이 나올 수도 있다는 것입니다.
실제로는 expected와 현재 값이 같은데도 실패할 수도 있다는 건데, 대부분의 경우 compare_exchange를 loop 내에서 실행하기 때문에 _weak를 사용해도 괜찮습니다. (최적화가 더 잘 되어 있습니다.)
하지만 만약 compare_exchange를 loop와 병행해서 사용하는 것이 아니라 단독으로 사용한다면, _strong을 사용하는 것이 맞습니다.
