BwTree Update Code & Performance Evaluation
현재 OpenBwTree에는 Update가 구현되어 있지 않습니다.
그렇기에 테스트 케이스 생성에 앞서 BwTree를 위한 Update를 제작해야 했습니다.
- Update Implementation
- Uniform Update Performance Results
- Skew Update Performance Results
- Result Analyzation
- Next things to do
Update Implementation
함수 원형
bool Update(const KeyType &key, const ValueType &oldValue, const ValueType &newValue)
OpenBwTree는 기본적으로 one key - multi value의 형태로 이루어져 있습니다.
그렇기 때문에 Update를 위해서는 Update할 정확한 (key-value) 쌍을 알아야합니다.
구현
Update()의 진행은 크게 3파트로 나눌 수 있습니다.
- find: 해당 (key, oldValue), (key, newValue)의 존재 유무 확인
- delete: (key, oldValue) 튜플 삭제
- insert: (key, newValue) 튜플 삽입
실제 구현에서는 다음과 같이 진행합니다.
void TraverseReadOptimized(Context *context_p, std::vector<ValueType> *value_list_p)함수를 사용하여 해당 key가 가지고 있는 모든 value 쌍을 하나의 vector container에 가져옵니다.
해당 리턴 값 내에 oldValue가 존재하고, newValue가 존재하지 않을 때만 이후 과정을 진행합니다.
만약 oldValue가 존재하지 않거나, newValue가 이미 존재할 경우 Update는 abort 됩니다.bool Delete(const KeyType &key, const ValueType &value)함수를 참고하여 BwTree 내에 delete node를 삽입합니다.bool Insert(const KeyType &key, const ValueType &value)함수를 참고하여 BwTree 내에 insert node를 삽입합니다.
주의
Update 함수의 성능을 평가하는 테스트 코드 생성의 편의성을 위하여 동일 value 값의 update (ex: update(5, 4, 4))를 막지 않았습니다.
즉 해당 예제의 경우 key:5의 oldValue 4의 삭제를 진행한 이후 새롭게 newValue 4를 insert 합니다.
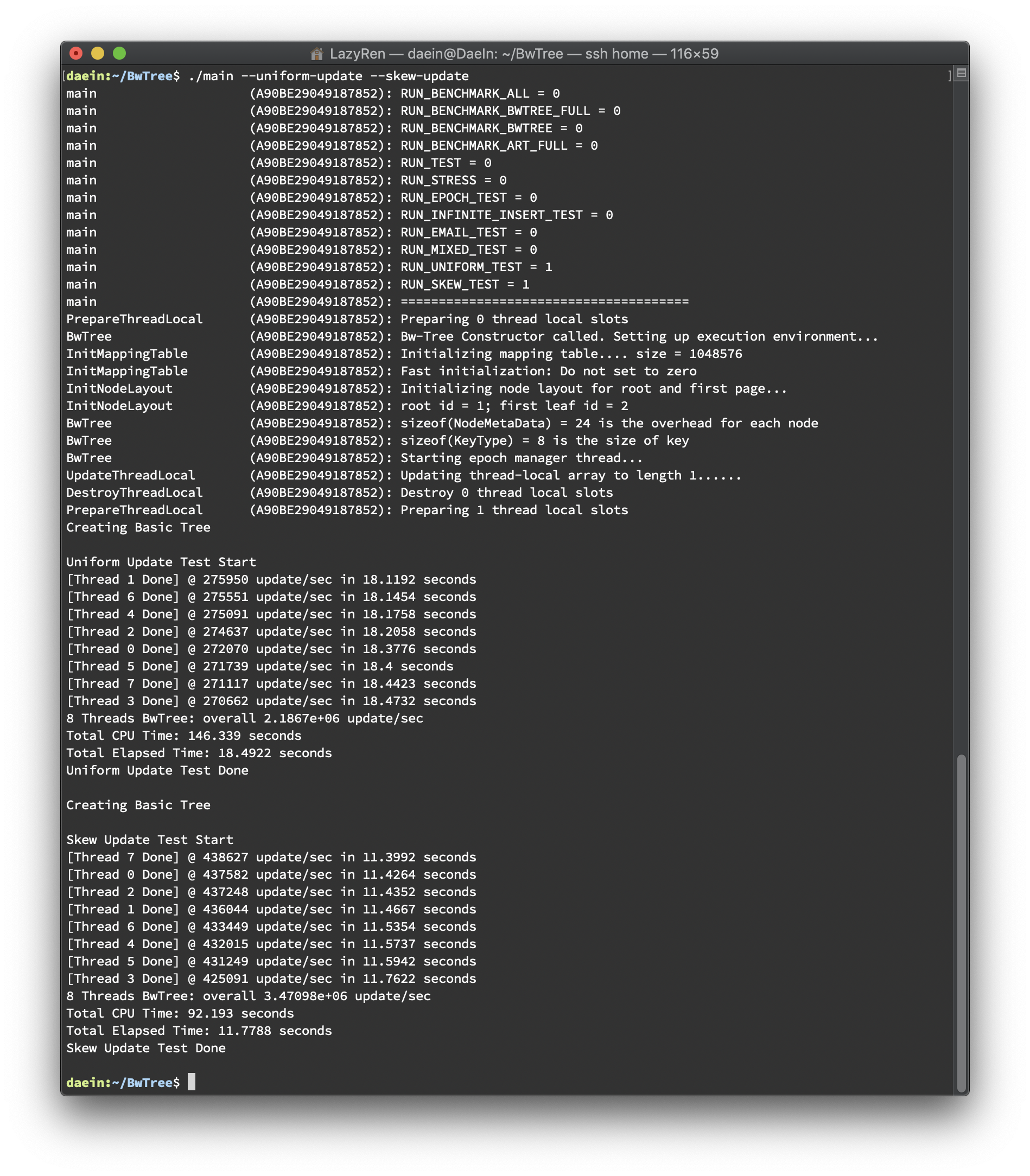
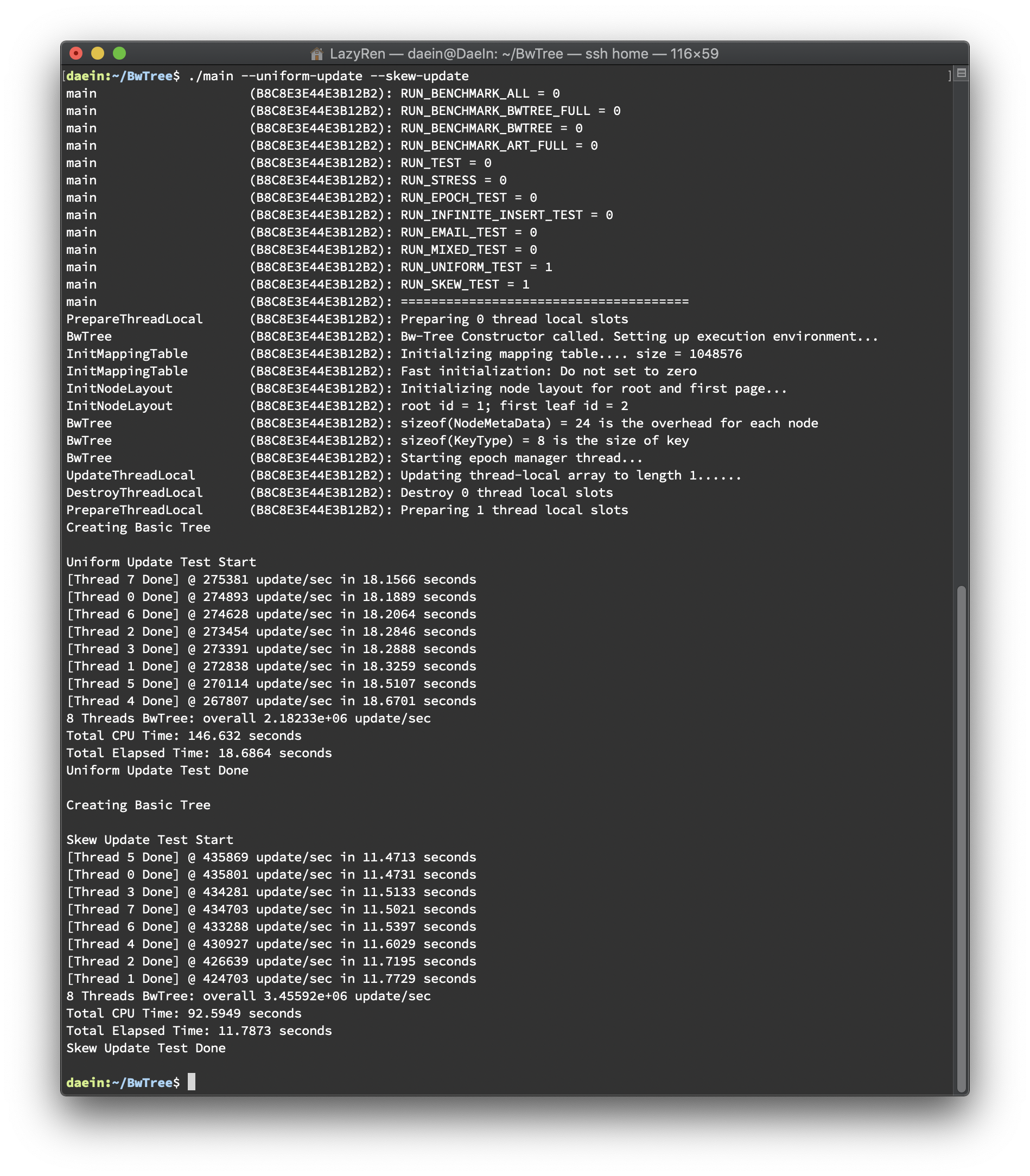
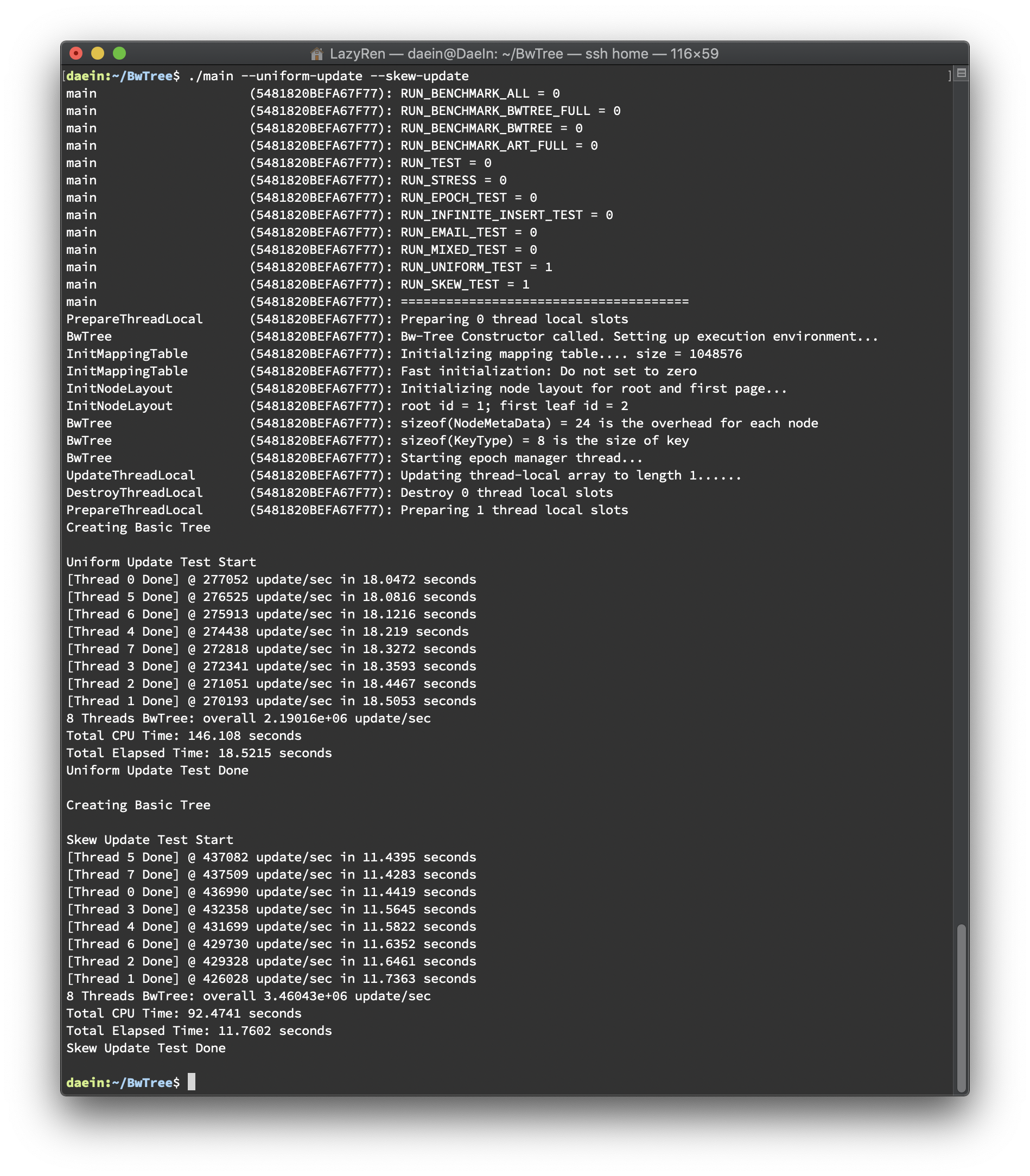
Uniform Update Performance Results
20.20%
const KeyValuePair *Traverse(Context *context_p, const ValueType *value_p, std::pair<int, bool> *index_pair_p)
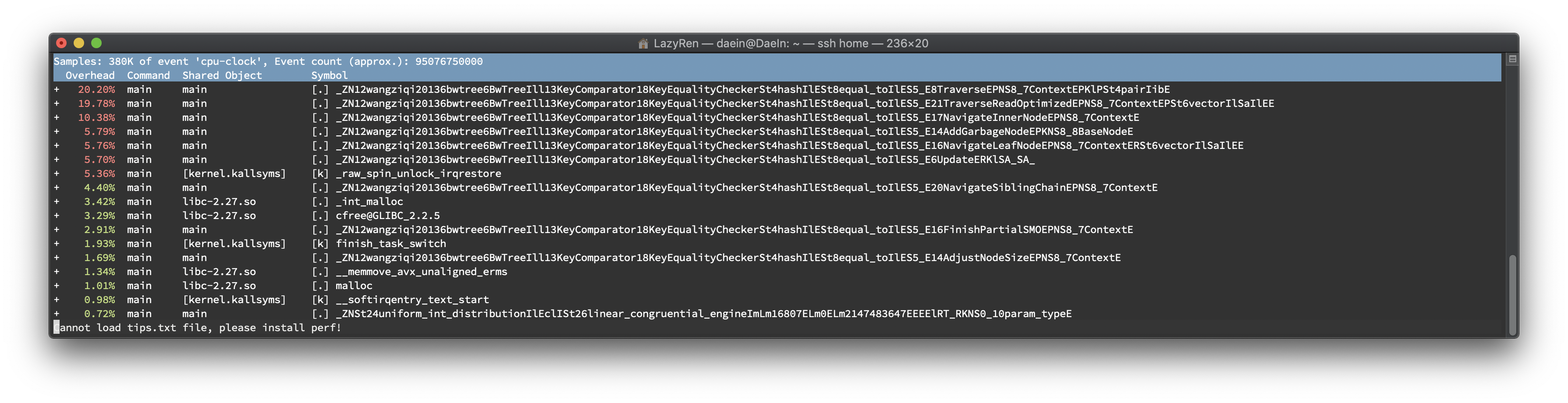
새롭게 구현한Update()함수는 기존의Delete(),Insert()함수의 코드를 활용하였기 때문에 <Key, Value> 페어의 삭제, 삽입에Traverse()함수를 사용합니다. 만약 이 때 CaS가 실패했을 경우Traverse()가 재호출 되기 때문에 가장 높은 점유율을 가질 것으로 예상했었고 실제 테스트에서 증명되었습니다.19.78%
void TraverseReadOptimized(Context *context_p, std::vector<ValueType> *value_list_p)
Update()진행시에 가장 먼저 호출되는 함수 입니다. BwTree를 순회하면서 해당 key가 가지고 있는 모든 value를 반환합니다. 이를 위해 많은 양의 연산이 소요됩니다.10.38%
NodeID NavigateInnerNode(Context *context_p)
TraverseReadOptimized()함수와Traverse()함수에서 leaf node에 도달하기 전까지 무한 반복문 내에서 inner node를 모두 탐색하는 함수입니다. 가장 많은 양의 호출이 있으며, Update에는 Traverse류의 함수가 3회나 호출 되기 때문에 높은 %를 나타내고 있습니다.5.79%
void AddGarbageNode(const BaseNode *node_p)
다수의 delete/insert node 가 leaf node에 삽입 됨에 따라 node split이 빈번하게 발생하고 이로 인해 AddGarbageNode가 자주 호출 되며, garbage node list에 삽입을 CAS를 통해 해결하기 때문에 여러 스레드 접근시 한 번 호출되었을 때 여러번 spin이 도는 경우가 있습니다.5.76%
void NavigateLeafNode(Context *context_p, std::vector<ValueType> &value_list)
Traverse 함수 내에서 호출되는 함수입니다. Leaf node에서 key를 찾은 후 연관된 value들을 모으는 함수입니다. Delta chain의 끝에서부터 순회하며 merge와 split을 처리합니다.5.70%
bool Update(const KeyType &key, const ValueType &oldValue, const ValueType &newValue)
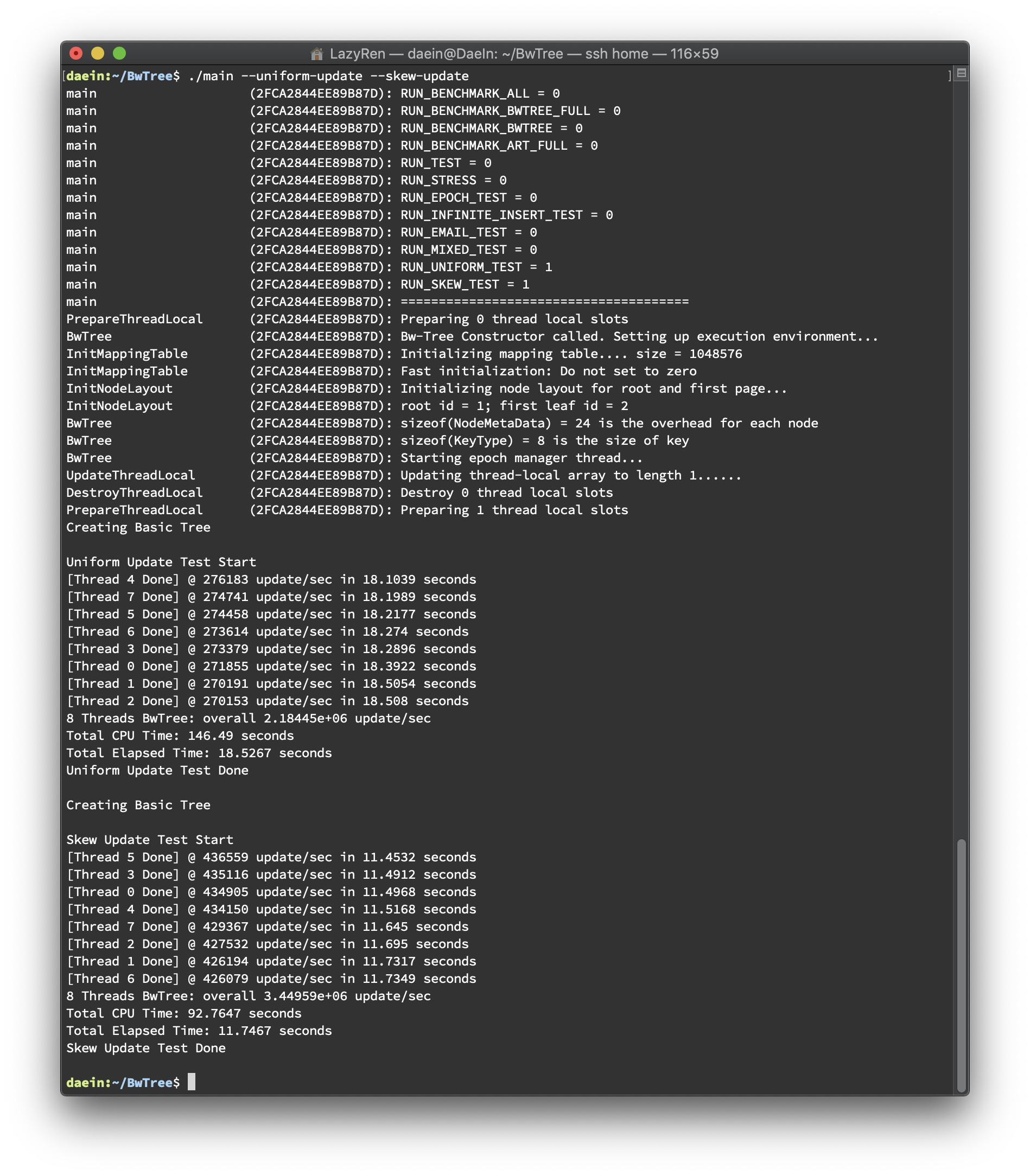
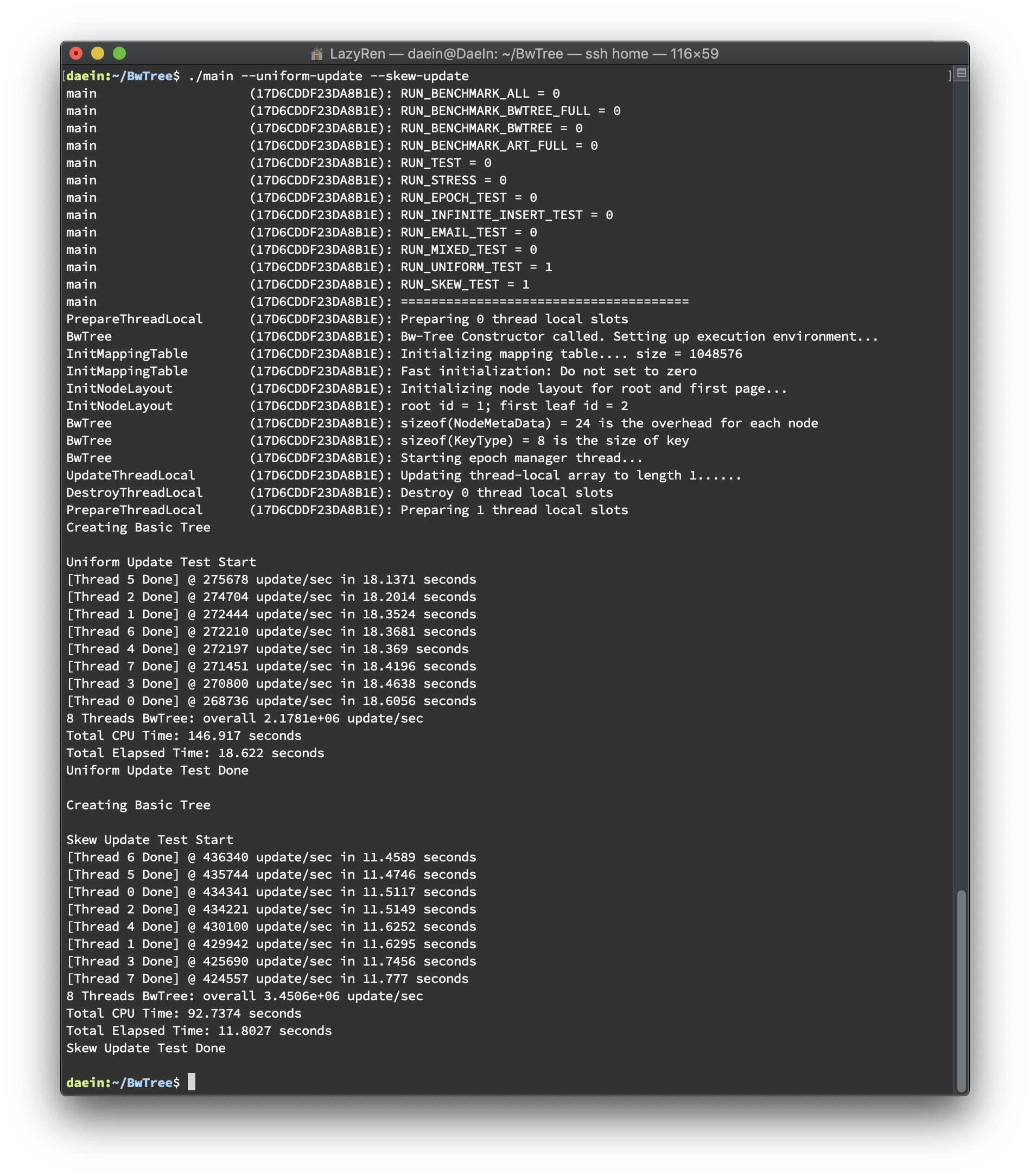
Skew Update Performance Results
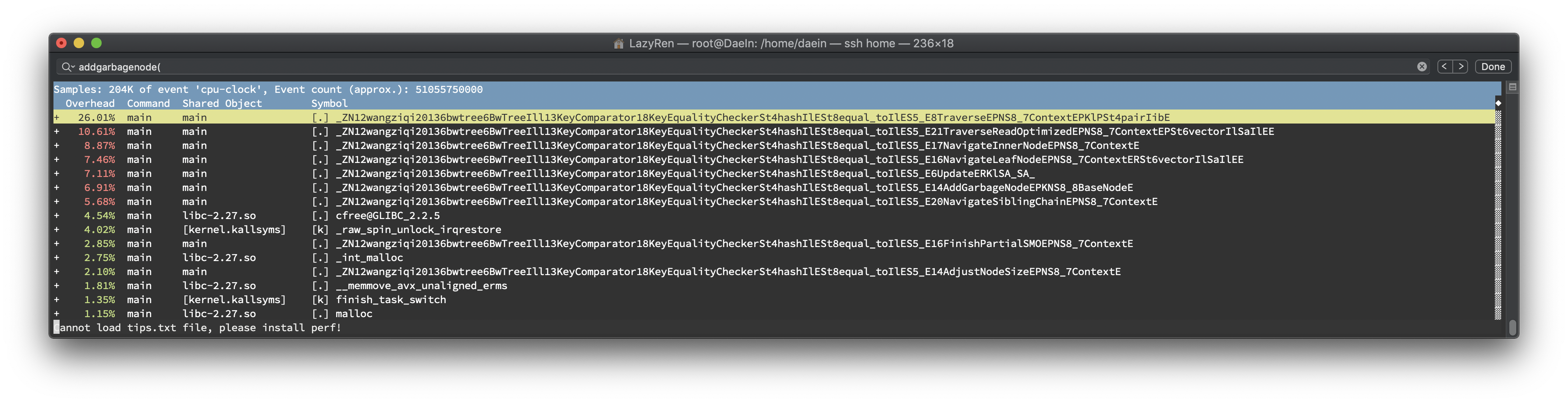
26.01%
const KeyValuePair *Traverse(Context *context_p, const ValueType *value_p, std::pair<int, bool> *index_pair_p)
새롭게 구현한Update()함수는 기존의Delete(),Insert()함수의 코드를 활용하였기 때문에 <Key, Value> 페어의 삭제, 삽입에Traverse()함수를 사용합니다. 만약 이 때 CaS가 실패했을 경우Traverse()가 재호출 되기 때문에 가장 높은 점유율을 가질 것으로 예상했었고 실제 테스트에서 증명되었습니다.10.61%
void TraverseReadOptimized(Context *context_p, std::vector<ValueType> *value_list_p)
Update()진행시에 가장 먼저 호출되는 함수 입니다. BwTree를 순회하면서 해당 key가 가지고 있는 모든 value를 반환합니다. 이를 위해 많은 양의 연산이 소요됩니다.8.87%
NodeID NavigateInnerNode(Context *context_p)
TraverseReadOptimized()함수와Traverse()함수에서 leaf node에 도달하기 전까지 무한 반복문 내에서 inner node를 모두 탐색하는 함수입니다. 가장 많은 양의 호출이 있으며, Update에는 Traverse류의 함수가 3회나 호출 되기 때문에 높은 %를 나타내고 있습니다.7.46%
void NavigateLeafNode(Context *context_p, std::vector<ValueType> &value_list)
Traverse 함수 내에서 호출되는 함수입니다. Leaf node에서 key를 찾은 후 연관된 value들을 모으는 함수입니다. Delta chain의 끝에서부터 순회하며 merge와 split을 처리합니다.7.11%
bool Update(const KeyType &key, const ValueType &oldValue, const ValueType &newValue)6.91%
void AddGarbageNode(const BaseNode *node_p)
다수의 delete/insert node 가 leaf node에 삽입 됨에 따라 node split이 빈번하게 발생하고 이로 인해 AddGarbageNode가 자주 호출 되며, garbage node list에 삽입을 CAS를 통해 해결하기 때문에 여러 스레드 접근시 한 번 호출되었을 때 여러번 spin이 도는 경우가 있습니다.5.68%
void NavigateSiblingChain(Context *context_p)
Result Analyzation
총 다섯 번의 테스트를 바탕으로 결과를 분석했습니다(하단 이미지 첨부). 테스트 환경은 아래와 같습니다.
하드웨어 스펙
CPU: Intel Core i7-6700 3.40GHz
RAM: 16GB
on VirtualBox Ubuntu 18.04 with 8 cores, 8 GB RAM
8 threads
40,000,000 update() call
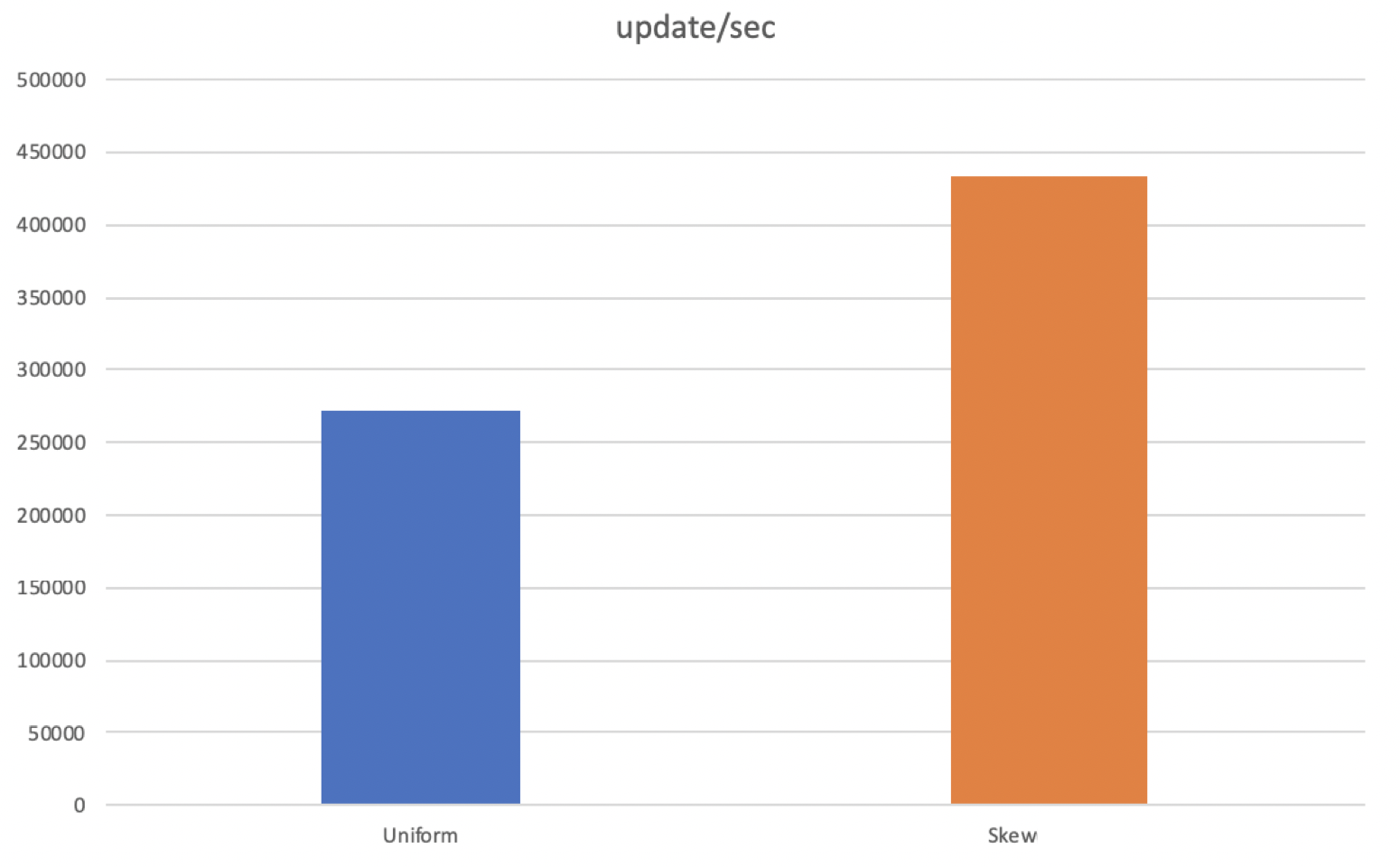
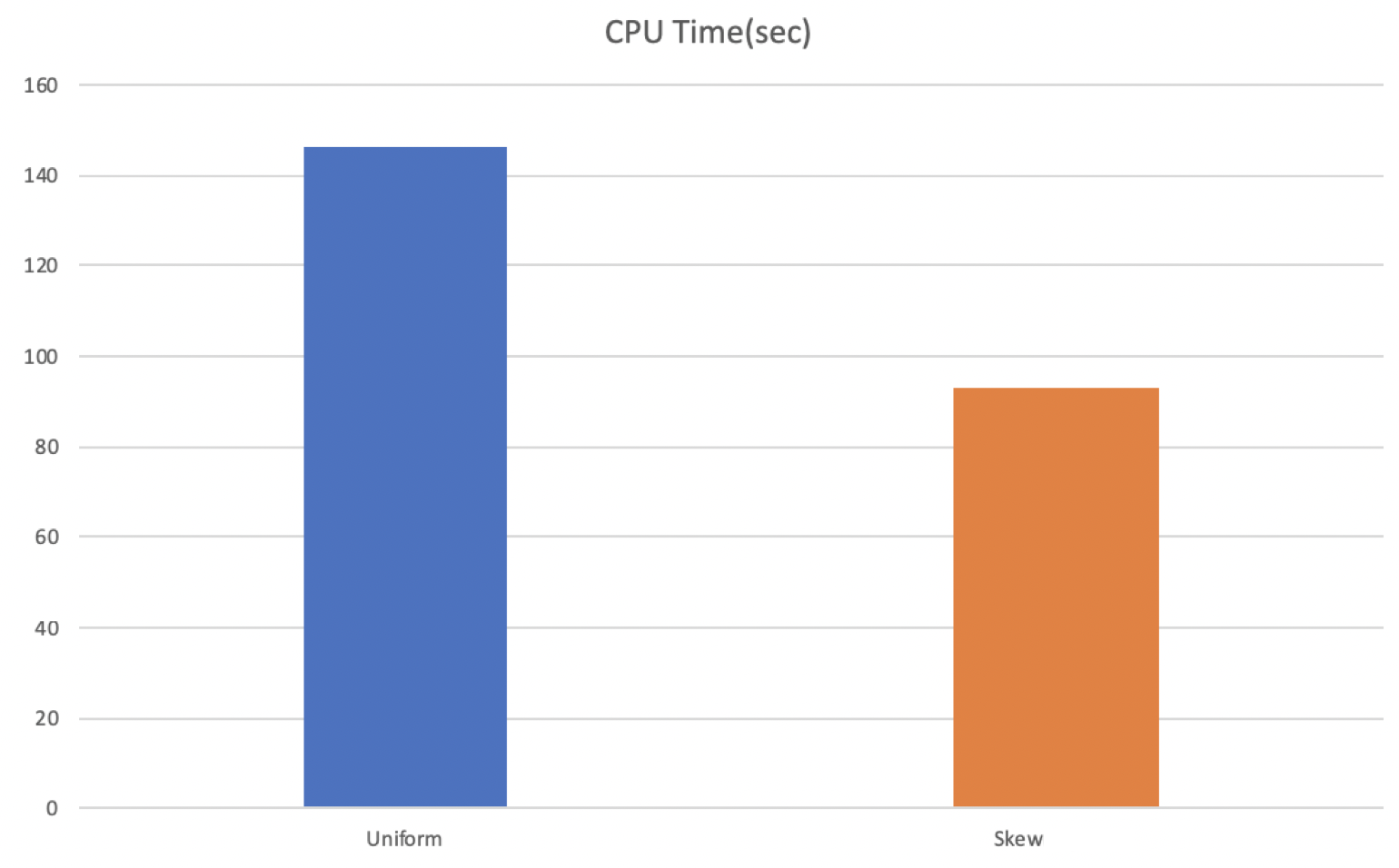
테스트는 update를 uniform한 경우와 skew된 경우를 비교해보기 위한 목적으로 진행되었습니다. Uniform Test는 stl에서 지원하는 uniform distribution을 이용하여 진행하였고, Skew Test는 전체 키 중 1/16만 업데이트하도록 진행하였습니다. 두 테스트 모두 seed를 random하게 바꿔주어 테스트별로 같은 값이 나오지 않도록 하였습니다. 결과는 스레드 별로 초당 업데이트 횟수를 출력하도록 했으며 총 소요시간을 마지막에 출력하도록 했습니다. 결과는 아래와 같습니다.
update/sec
CPU Time
Elapsed Time(per thread)
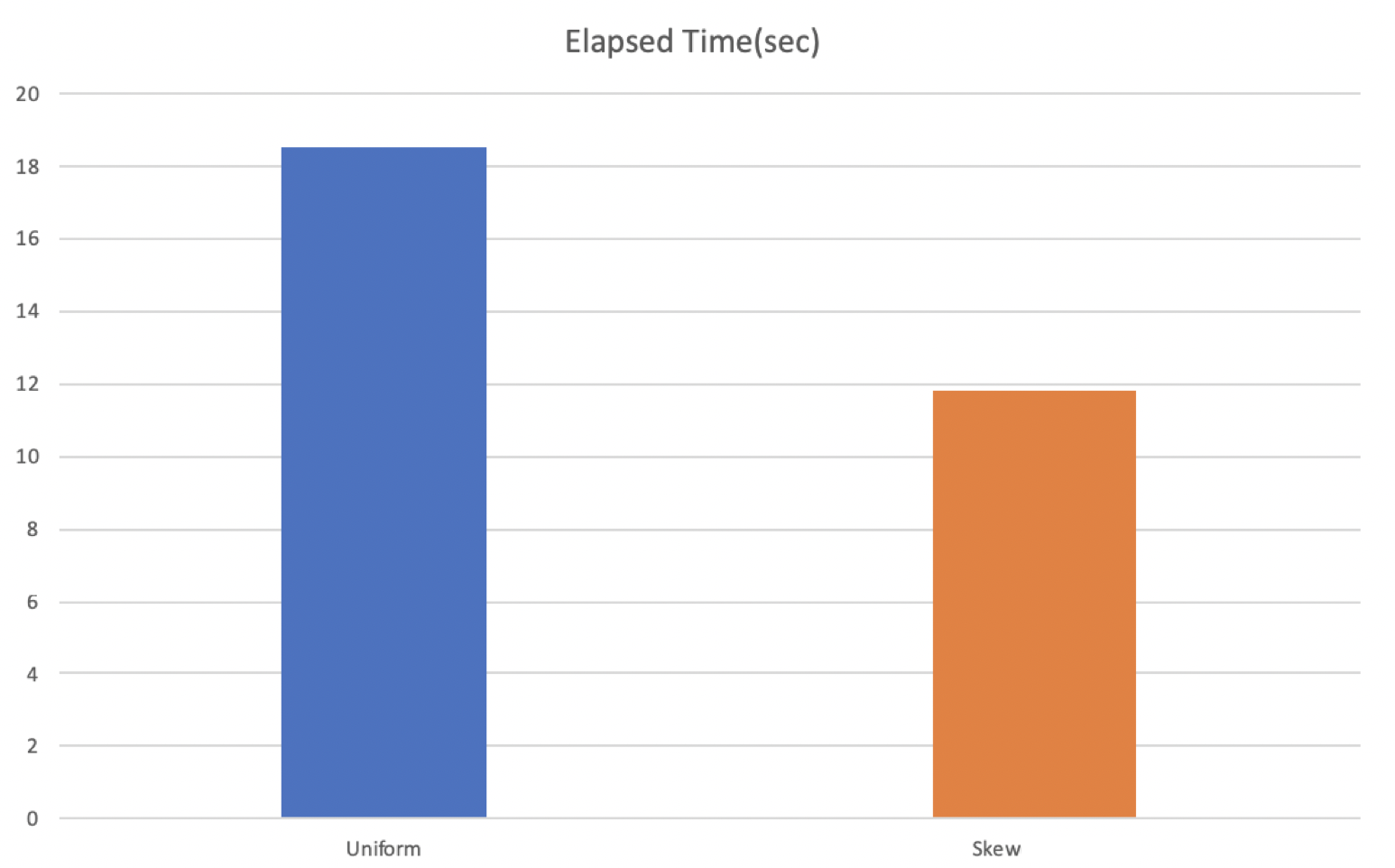
처음에 테스트를 진행하기 전에 예상하였던 결과는 skew된 상황에서 더 오래걸릴 것으로 예상하였습니다. 같은 delta chain에 대해서 CaS를 시도하면 Abort가 증가할 것이라 예상하였고, 이는 성능 저하로 이뤄질 것으로 생각되었습니다. 결과는 예상과 달랐고 이유를 분석해보았습니다. perf를 사용하여 함수별 overhead를 체크했을 때, 유의미한 overhead의 변화를 보였던 함수는 void TraverseReadOptimized(Context *context_p, std::vector<ValueType> *value_list_p) 였습니다. 이 함수는 bool Update(const KeyType &key, const ValueType &oldValue, const ValueType &newValue) 가 호출될 때 같이 호출되는 함수인데, Uniform Test 의 경우에는 update()의 overhead 대비 TraverseReadOptimized()의 overhead가 3.47인 반면에 Skew Test 의 경우에는 1.49에 불과했습니다. update() 함수 내부의 logic이 두 테스트 모두 거의 비슷한 정도의 오버헤드를 생성하게 되어있으므로, Skew Test 의 경우에는 TraverseReadOptimized()의 overhead가 작았다는 것을 의미합니다. 함수의 logic이 트리를 순회하도록 되어있는데, Skew Test 에서 abort가 일어나는 overhead를 이미 대부분의 page들이 cache에 이미 있었기 때문에 오히려 더 빠른 결과를 낳은 것이라고 생각됩니다.
두번째로, abort가 자주 일어날 것으로 예상하였던 Skew된 상황에서 Uniform한 상황과 비슷한 수준으로 consolidation overhead가 나타나고 있습니다. 이는 생각보다 abort가 성능에 미치지 않는다는 것을 의미하는 것인지 다음 보고서 때 다시 분석하여 제출하도록 하겠습니다. Skew된 상황에서는 Delta Chain이 빠르게 길이가 길어지고, 이는 consolidation의 빈도를 높이는 결과를 낳기 때문에 그렇게 될 것으로 판단했었습니다.
또한 Skew Test 에서 NavigateLeafNode() 의 점유율이 높게 나타났는데, 이는 예상하였던 부분으로 Skew Test의 경우 업데이트가 진행되는 Leaf Node에 한하여 Uniform Test의 16배의 Update() 가 일어나게 되므로 그만큼 많은 양의 delta node가 생성되고, 긴 delta chain이 즉각적인 NavigateLeafNode() 시간의 증가를 불러온 것이라고 판단됩니다.
Next things to do
- Cache에 대해서 출력하는 함수가 제대로 동작하고 있지 않습니다.
이 부분에 대해서 구글링을 좀 더 많이하여 실제 cache hit ratio를 비교해보겠습니다. - 현재 구현한
Update()함수는getValue(),Delete(),Insert()함수의 구현을 하나로 합친 것에 가깝습니다.
하나의 Epoch 내에 존재하는 만큼 불필요한 부분을 더 쳐내고 최적화 할 수 있는 방안에 대하여 생각해보겠습니다.
ex)Insert()진행시에Delete()가 사용한 context_p를 사용하여 진행(이미 해당 key가 존재하던 leafNode를 찾았기 때문에) - Consolidation의 overhead를 측정할 수 있는 방법을 생각해보겠습니다.